
python爬虫
前言
学习视频:尚硅谷
学习前最好是有一定的python基础,学习的效率会更加的好。
CTRL + / 快速注释
1.前提知识
1.序列化与反序列化
1.概念
通过文件操作,可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。
- 对象—>字节序列 === 序列化
- 字节序列—>对象 ===反序列化
Python中提供了JSON这个模块用来实现数据的序列化和反序列化。
2.序列化的实现
1 | ''' |
3.反序列化的实现
1 | # 字节序列 变为 对象 == 反序列化 |
2.异常
1.概念
程序在运行过程中,由于编码不规范,或者其他原因一些客观原因,导致程序无法继续运行,此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的健壮性,我们在程序设计里提出了异常处理这个概念。
2.try…except语句
1 | # 语法: |
3.网页页面结构的介绍
1.html文件
新建一个.html文件,初始的主体为:
1 |
|
2.html的标签介绍
1 |
|
4.URL(统一资源定位符)组成
1 | #url的组成:协议(http/https),主机(www.baidu.com),端口号(80/443),路径,参数,锚点 |
5.什么是互联网爬虫
- 解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息
- 解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
6.爬虫核心
- 爬取网页:爬取整个网页,包含了网页中所有的内容
- 解析数据:将网页中得到的数据进行解析
- 难点:爬虫与反爬虫之间的博弈
7.爬虫的用途
- 数据分析/人工数据集
- 社交软件冷启动
- 竞争对手的监控
- 舆情监控
8.爬虫的分类
1.通用爬虫(不是我们学习的)
1 | 实例: |
2.聚焦爬虫
1 | 功能: |
9.反爬虫手段?
1 | 1.User‐Agent: |
2.Urllib
1.urllib库使用
1 | urllib.request.urlopen() 模拟浏览器向服务器发送请求 |
1.urllib的基本使用
1 | # 使用urllib来获取百度首页的源码 |
2.Urllib的1个类型和6个方法
1 | import urllib.request |
3.Urllib的下载
1 | # urlretrieve(url,filename):url 下载路径,filename 文件的名字 |
2.请求对象的定制
1.UA介绍:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
1 | 语法: |
2.UA反爬
1 | #第一个反爬 |
3.扩展:编码
- ASCII编码:127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号。
- GB2312编码:用来把中文编进去。
- Unicode:最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
3.编/解码
1.get请求方式:urllib.parse.quote()
将汉字变成Unicode编码
1 | # 语法: |
实际例子:
1 | ''' |
2.get请求方式:urllib.parse.urlencode()
- 作用:将字典中多个中文转换成Unicode编码,并且键值之间使用“=”连接,键值对之外使用&连接。
1 | 语法格式: |
- 实际例子:
1 | # urlencode应用场景:多个中文参数 |
3.post请求方式
步骤:
- 找post 请求的接口
- 怎么执行post请求(请求参数进行编码。编码之后 必须调用encode方法。)
- 传参数
1 | # post请求 |
4.总结:post和get区别?
- get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
- post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
5.百度翻译之详细翻译
1 | import urllib.request |
4.ajax的get请求
- 案例1:豆瓣电影第一页
1 | # get请求 |
- 案例2:豆瓣电影前10页
1 | ''' |
5.ajax的post请求
- 案例:爬取肯德基官网
1 | ''' |
6.URLError\HTTPError
1 | 简介: |
- 案例:
1 | import urllib.request |
7.cookie登录
- 案例:微博登录
1 | ''' |
8.Handler处理器
1 | 为什么要学习handler? |
- 案例:handler的基本使用
1 | import urllib.request |
9.代理服务器
1 | 1.代理的常用功能? |
- 案例1:快代理
1 | import urllib.request |
- 案例2:代理池
1 | import random |
3.解析
1.xpath
- 安装xpath
1 | xpath使用: |
- xpath的基本语法
1 | 1.路径查询 |
例子演示:
数据的准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<ul>
<li>大连</li>
<li>锦州</li>
<li>沈阳</li>
</ul>
</body>
</html>演示的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39from lxml import etree
'''
xpath解析
(1)本地文件
html_tree = etree.parse('XX.html')
(2)服务器相应的数据
html_tree = etree.HTML(response.read().decode('utf‐8')
'''
# xpath解析本地文件
tree = etree.parse('1.解析_xpath的基本使用.html')
# tree.xpath('xpath的路径')
# (1)查找ul下的li
li_list = tree.xpath('//body/ul/li')
print(len(li_list))
# (2)谓词查询 需求:查找所有id属性的li标签
li_list = tree.xpath('//ul/li[@id]')
print(len(li_list))
# (3)查找id为l1的li标签
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list)
# (4)查找到id为l1的li标签的class的属性值
li = tree.xpath('//ul/li[@id="l1"]/@class')
print(li,len(li))
# (5)查询id中包含l的li标签
li = tree.xpath('//ul/li[contains(@id, "l")]/text()')
print(li,len(li))
# (6)查询id的值以l开头的li标签
li = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li,len(li))
# (7)逻辑运算 查询id为l1和class为c1的
li = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
print(li,len(li))
li = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
print(li,len(li))
案例1:获取百度网站的:”百度一下”
1 | ''' |
- 案例:站长素材
1 | ''' |
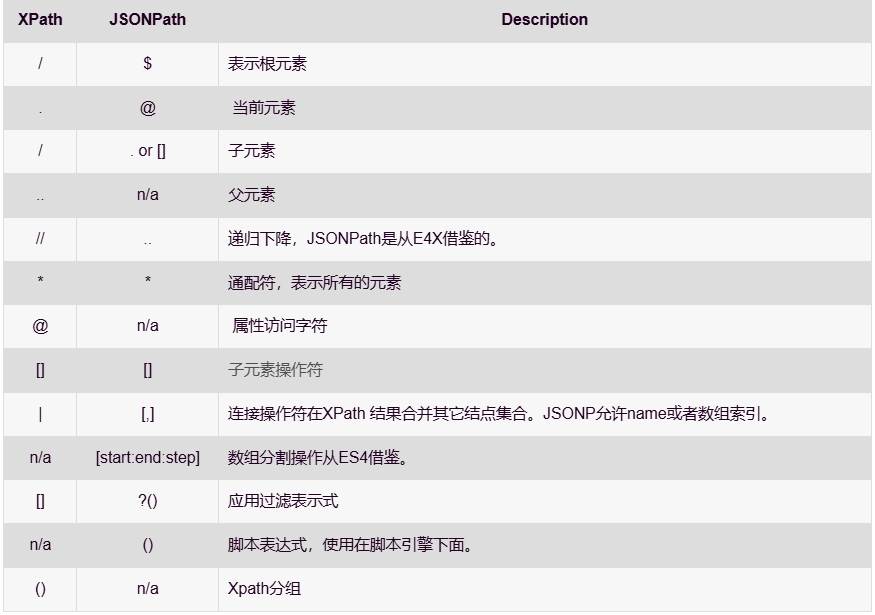
2.JsonPath
- 只能识别本地文件
安装与使用
1
2
3
4
5pip安装:
pip install jsonpath
jsonpath的使用:
obj = json.load(open('json文件路径', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath语法')
案例(淘票票)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
content = content.split('(')[1].split(')')[0]
with open('5._解析_jsonpath解析淘票票.json','w',encoding='utf-8') as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('5._解析_jsonpath解析淘票票.json','r',encoding='utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)
3.BeautifulSoup
基本简介
1
2
3
4
5
6
71.BeautifulSoup简称:
bs4
2.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?
缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便安装以及创建
1
2
3
4
5
6
7
8
9
101.安装
pip install bs4
2.导入
from bs4 import BeautifulSoup
3.创建对象
服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(), 'lxml')
本地文件生成对象
soup = BeautifulSoup(open('6.解析_bs4的基本使用.html',encoding='utf-8'),'lxml')
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式节点定位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
311.根据标签名查找节点
soup.a 【注】只能找到第一个a
soup.a.name
soup.a.attrs # 获取标签的属性和属性值
2.函数
(1).find(返回一个对象)
find('a'):只找到第一个a标签
(2).find_all(返回一个列表)
find_all('a') 查找到所有的a
find_all(['a', 'span']) 返回所有的a和span
find_all('a', limit=2) 只找前两个a
(3).select(根据选择器得到节点对象)【推荐】
1.element
eg:p
2..class
eg:.firstname
3.#id
eg:#firstname
4.属性选择器
[attribute]
eg:li = soup.select('li[class]')
[attribute=value]
eg:li = soup.select('li[class="hengheng1"]')
5.层级选择器
element element
div p
element>element
div>p
element,element
div,p
eg:soup = soup.select('a,span')节点信息
1
2
3
4
5
6
7
8
9
10
11
12(1).获取节点内容:适用于标签中嵌套标签的结构
obj.string
obj.get_text()【推荐】
(2).节点的属性
tag.name 获取标签名
eg:tag = find('li)
print(tag.name)
tag.attrs将属性值作为一个字典返回
(3).获取节点属性
obj.attrs.get('title')【常用】
obj.get('title')
obj['title']案例(星巴克数据)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 时间问题,代码已经失效
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())
4.selenium
1.selenium概述
selenium概念
1
2
3
4(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。为什么使用selenium
1
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
安装selenium
1
2
3
4
5
6
7(1)操作谷歌浏览器驱动下载地址
http://chromedriver.storage.googleapis.com/index.html
(2)谷歌驱动和谷歌浏览器版本之间的映射表
http://blog.csdn.net/huilan_same/article/details/51896672
(3)查看谷歌浏览器版本
谷歌浏览器右上角‐‐>帮助‐‐>关于
(4)pip install seleniumselenium的使用步骤
1
2
3
4
5
6
7(1)导入:from selenium import webdriver
(2)创建谷歌浏览器操作对象:
path = 谷歌浏览器驱动文件路径
browser = webdriver.Chrome(path)
(3)访问网址
url = 要访问的网址
browser.get(url)selenium的元素定位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,WebDriver提供很多定位元素的方法
方法:
1.find_element_by_id
eg:button = browser.find_element_by_id('su')
2.find_elements_by_name
eg:name = browser.find_element_by_name('wd')
3.find_elements_by_xpath
eg:xpath1 = browser.find_elements_by_xpath('//input[@id="su"]')
4.find_elements_by_tag_name
eg:names = browser.find_elements_by_tag_name('input')
5.find_elements_by_css_selector
eg:my_input = browser.find_elements_by_css_selector('#kw')[0]
6.find_elements_by_link_text
eg:browser.find_element_by_link_text("新闻")访问元素信息
1
2
3
4
5
61.获取元素属性
.get_attribute('class')
2.获取元素文本
.text
3.获取标签名
.tag_name交互
1
2
3
4
5
6
7
8
9点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动:
js='document.documentElement.scrollTop=100000'
browser.execute_script(js) 执行js代码
获取网页代码:page_source
退出:browser.quit()
2.Chrome handless
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致
系统要求:
1
2
3
4
5
6Chrome
Unix\Linux 系统需要 chrome >= 59
Windows 系统需要 chrome >= 60
Python3.6
Selenium==3.4.*
ChromeDriver==2.31配置:
1
2
3
4
5
6
7
8
9
10
11
12from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('‐‐headless')
chrome_options.add_argument('‐‐disable‐gpu')
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://www.baidu.com/')配置封装:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from selenium import webdriver
#这个是浏览器自带的 不需要再做额外的操作
from selenium.webdriver.chrome.options import Options
def share_browser():
#初始化
chrome_options = Options()
chrome_options.add_argument('‐‐headless')
chrome_options.add_argument('‐‐disable‐gpu')
#浏览器的安装路径 打开文件位置
#这个路径是你谷歌浏览器的路径
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
return browser封装调用
1
2
3
4
5
6
7from handless import share_browser
browser = share_browser()
browser.get('http://www.baidu.com/')
browser.save_screenshot('handless1.png')
5.requests
1.基本使用
文档
1
2
3
4官方文档
http://cn.python‐requests.org/zh_CN/latest/
快速上手
http://cn.python‐requests.org/zh_CN/latest/user/quickstart.html安装
1
pip install requests
response的属性以及类型
1
2
3
4
5
6
7类型 :models.Response
r.text :获取网站源码
r.encoding :访问或定制编码方式
r.url :获取请求的url
r.content :响应的字节类型
r.status_code :响应的状态码
r.headers :响应的头信息
2.get请求
1 | requests.get() |
3.post请求
1 | requests.post() |
- get和post区别?
- get请求的参数名字是params post请求的参数的名字是data
- 请求资源路径后面可以不加?
- 不需要手动编解码
- 不需要做请求对象的定制
4.代理
1 | ''' |
5.cookie定制
1 | 应用案例: |
6.scrapy
1.scrapy概述
1.认识scrapy
scrapy是什么?
1
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装scrapy:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22pip install scrapy
(1)安装出错,且报错信息:
pip install Scrapy
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual‐cpp‐build‐tools
解决方案:
1.进入:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
2.下载twisted对应版本的whl文件(如Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl),cp后面是 python版本,amd64代表64位
3.运行命令:
pip install C:\Users\...\Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl # 本地文件
pip install Scrapy
(2)若再报错
python ‐m pip install ‐‐upgrade pip
(3)若再报错:win32
解决方法:
pip install pypiwin32
(4)若再报错:使用anaconda
2.scrapy项目的创建以及运行
创建scrapy项目,在终端输入:
1
scrapy startproject 项目名称
项目组成:
1
2
3
4
5
6
7
8spiders # 存储爬虫文件
__init__.py
自定义的爬虫文件.py # 由我们自己创建,是实现爬虫核心功能的文件
__init__.py
items.py # 定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py # 中间件,代理
pipelines.py # 管道文件,里面只有一个类,用于处理下载数据的后续处理[默认是300优先级,值越小优先级越高(1‐1000)]
settings.py # 配置文件 比如:是否遵守robots协议,User‐Agent定义等创建爬虫文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15创建爬虫文件:
(1)跳转到spiders文件夹:cd 目录名字/目录名字/spiders
(2)scrapy genspider 爬虫名字 网页的域名(一般不写http://)
eg:scrapy genspider baidu www.baidu.com
爬虫文件的基本组成(继承scrapy.Spider类):
name = 'baidu' # 运行爬虫文件时使用的名字
allowed_domains # 爬虫允许的域名,在爬取的时候,如果不是此域名之下的url,会被过滤掉
start_urls # 声明了爬虫的起始地址,可以写多个url,一般只有一个。注:html的url最后不能有/
parse(self, response) # 解析数据的回调函数
response.text # 响应的是字符串
response.body # 响应的是二进制文件
response.xpath() # xpath方法的返回值类型是selector列表
extract() # 提取的是selector对象的是data
extract_first() # 提取的是selector列表中的第一个数据运行爬虫文件,cmd输入:
1
2scrapy crawl 爬虫名称
注意:应在spiders文件夹内执行
3.scrapy架构组成
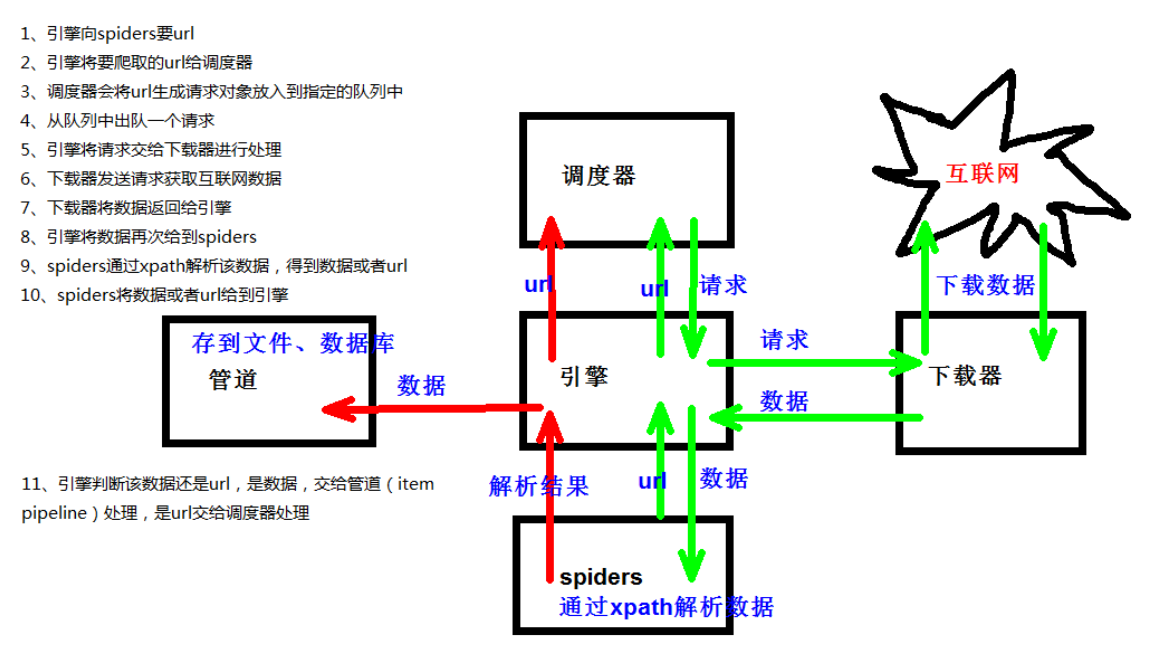
1 | (1)引擎:自动运行,无需关注,会自动组织所有的请求对象,分发给下载器 |
4.scrapy工作原理
2.scrapy shell
scrapy shell介绍
1
2Scrapy终端,是一个交互终端,在未启动spider的情况下尝试及调试爬取代码。 其本意是用来测试提取数据的代码,可将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写spider时,该终端提供了交互性测试表达式代码的功能,免去了每次修改后运行spider的麻烦。一旦熟悉了Scrapy终端后,其在开发和调试spider时发挥的巨大作用。安装ipython
1
pip install ipython
应用
1
2
3(1)scrapy shell www.baidu.com
(2)scrapy shell http://www.baidu.com
(3) scrapy shell "http://www.baidu.com"
3.yield
1.概念
- 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
- yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
- 简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始
2.案例1(按页下载):爬取汇书网
创建项目:切换到项目存放目录,创建项目。
1
2
3cd C:\Users\wuhen\Desktop
scrapy startproject hsw创建爬虫文件:进入爬虫存储文件,创建爬虫。
1
2
3cd hsw/hsw/spiders
scrapy genspider hsw_spider https://www.huibooks.com/wx爬虫运行:
1
2运行代码
scrapy crawl hsw_spider编写爬虫:打开项目,检查hsw_spider.py的name、allowed_domains、start_urls,编写初步的爬虫.(若运行报错,关闭settings.py的ROBOTSTXT_OBEY)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class HswSpiderSpider(scrapy.Spider):
name = "hsw_spider"
allowed_domains = ["www.huibooks.com"]
start_urls = ["https://www.huibooks.com/wx"]
def parse(self, response):
src_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@src')
name_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@alt')
number_list = response.xpath('//li[@class="post-list-meta-views"]/span/text()')
for i in range(len(src_list)):
src = src_list[i].extract()
name = name_list[i].extract()
number = number_list[i].extract()
print(src,name,number)定义数据结构:在items.py编写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class HswItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
name = scrapy.Field()
number = scrapy.Field()
管道文件:在pipelines.py下,处理下载的数据。
在settings.py打开:
1
2
3ITEM_PIPELINES = {
"hsw.pipelines.HswPipeline": 300,
}注:只能是open_spider和close_spider。写入时只能是字符串对象。
1
2
3
4
5
6
7
8
9
10class HswPipeline:
def open_spider(self, spider):
self.fp = open('books.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spidre):
self.fp.close()导入数据结构方面,创建数据结构,存储数据
在hsw_spider.py中输入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import scrapy
from hsw.items import HswItem
class HswSpiderSpider(scrapy.Spider):
name = "hsw_spider"
allowed_domains = ["www.huibooks.com"]
start_urls = ["https://www.huibooks.com/wx"]
def parse(self, response):
src_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@src')
name_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@alt')
number_list = response.xpath('//li[@class="post-list-meta-views"]/span/text()')
for i in range(len(src_list)):
src = src_list[i].extract()
name = name_list[i].extract()
number = number_list[i].extract()
book = HswItem(src=src, name=name, number=number)
yield book开启多条管道(注意shell运行的路径)
定义管道类:在pipelines.py下添加类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class HswPipeline:
def open_spider(self, spider):
self.fp = open('books.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spidre):
self.fp.close()
import urllib.request
class HswDownloadPipeline:
def process_item(self, item, spider):
url = item.get("src")
filename = './books/' + item.get("name") + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item在settings.py中开启管道
1
2
3
4ITEM_PIPELINES = {
"hsw.pipelines.HswPipeline": 300,
"hsw.pipelines.HswDownloadPipeline":301,
}
多页数据下载
找到url的规律
1
2
3# https://www.huibooks.com/wx
# https://www.huibooks.com/wx/page/2
# https://www.huibooks.com/wx/page/3调用hsw_spider.py中的parse函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import scrapy
from hsw.items import HswItem
class HswSpiderSpider(scrapy.Spider):
name = "hsw_spider"
allowed_domains = ["www.huibooks.com"]
start_urls = ["https://www.huibooks.com/wx"]
base_url = 'https://www.huibooks.com/wx/page/'
page = 1
def parse(self, response):
src_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@src')
name_list = response.xpath('//li[@class="post-list-item item-post-style-1"]//img/@alt')
number_list = response.xpath('//li[@class="post-list-meta-views"]/span/text()')
for i in range(len(src_list)):
src = src_list[i].extract()
name = name_list[i].extract()
number = number_list[i].extract()
book = HswItem(src=src, name=name, number=number)
yield book
# https://www.huibooks.com/wx
# https://www.huibooks.com/wx/page/2
# https://www.huibooks.com/wx/page/3
if self.page < 3:
self.page += 1
url = self.base_url + str(self.page)
# 调用parse方法
# scrapy.Request就是 scrapy 的get请求
yield scrapy.Request(url=url,callback=self.parse) # callback调用的函数,调用的函数不需要加()
3.案例2(多页下载):电影天堂
需求:一个item包含多级页面的数据
创建项目:切换到项目存放目录,创建项目。
1
2
3cd C:\Users\wuhen\Desktop
scrapy startproject dytt创建爬虫文件:进入爬虫存储文件,创建爬虫。
1
2
3cd dytt/dytt/spiders
scrapy genspider dytt_spider https://www.dyttcn.com/dongzuopian/list_1_1.html爬虫运行:
1
2运行代码
scrapy crawl hsw_spider定义数据结构:在items.py编写
1
2
3
4
5
6
7
8import scrapy
class DyttItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()编写爬虫:打开项目,检查hsw_spider.py的name、allowed_domains、start_urls,编写初步的爬虫.(注意meta传参)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import scrapy
from dytt.items import DyttItem
class DyttSpiderSpider(scrapy.Spider):
name = "dytt_spider"
allowed_domains = ["www.dyttcn.com"]
start_urls = ["https://www.dyttcn.com/dongzuopian/list_1_1.html"]
def parse(self, response):
# 要第一页的名字 和 第二页的图片
name_list = response.xpath('//table[@class="tbspan"]//a[@class="ulink"][2]/text()')
href_list = response.xpath('//table[@class="tbspan"]//a[@class="ulink"][1]/@href')
for i in range(len(name_list)):
name = name_list[i].extract()
href = href_list[i].extract()
# 第二页的地址
url = 'https://www.dyttcn.com' + href
# 访问第二页链接
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name}) # meta强行转换成字典
def parse_second(self,response):
# 若没有数据,修改xpath
src = response.xpath('//div[@id="Zoom"]/div[1]/img/@src').extract_first()
name = response.meta['name']
movie = DyttItem(name=name,src=src)
yield movie管道文件:在pipelines.py下,处理下载的数据。
在settings.py打开:
1
2
3ITEM_PIPELINES = {
"dytt.pipelines.DyttPipeline": 300,
}注:只能是open_spider和close_spider。写入时只能是字符串对象。
1
2
3
4
5
6
7
8
9
10class DyttPipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
4.CrawlSpider
1.概念
继承自scrapy.Spider
独门秘笈
- CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求
- 所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的
提取链接
1
2
3
4
5
6
7
8
9链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
allow = (), # 正则表达式 提取符合正则的链接
deny = (), # (不用)正则表达式 不提取符合正则的链接
allow_domains = (), # (不用)允许的域名
deny_domains = (), # (不用)不允许的域名
restrict_xpaths = (), # xpath,提取符合xpath规则的链接
restrict_css = () # 提取符合选择器规则的链接
)模拟使用
- 正则用法:links1 = LinkExtractor(allow=r’list_23_\d+.html’)
- xpath用法:links2 = LinkExtractor(restrict_xpaths=r’//div[@class=”x”]’)
- css用法:links3 = LinkExtractor(restrict_css=’.x’)
提取连接
1
link.extract_links(response)
注意事项
callback只能写函数名字符串, callback=’parse_item’
在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item
**注:**follow=true 是否跟进 就是按照提取连接规则进行提取
2.案例:读书网
创建项目
1
2
3cd C:\Users\wuhen\Desktop
scrapy startproject readbook创建爬虫文件
1
2
3cd readbook/readbook/spiders
scrapy genspider -t crawl read https://www.dushu.com/book/1188.html定义数据结构:在items.py编写
1
2
3
4
5class ReadbookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()编写爬虫:read.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from readbook.items import ReadbookItem
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
start_urls = ["https://www.dushu.com/book/1188_1.html"]
rules = (
Rule(LinkExtractor(allow=r"/book/1188_\d+\.html"),
callback="parse_item",
follow=False),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = ReadbookItem(name=name,src=src)
yield book管道文件:在settings.py打开管道。在pipelines.py下,处理下载的数据。
1
2
3
4
5
6
7
8
9
10
11
12class ReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()创建数据库与表
1
2
3
4
5
6
7
8
9create database spider01 charser=utf8;
use spider01
create table book(
id int primary key auto_increment,
name varchar(128),
src varchar(128)
);连接数据库:在settings.py任意位置输入
1
2
3
4
5
6
7# 数据库名字
DB_HOST = "localhost"
DB_PORT = 3306
DB_USER = "root"
DB_PASSWORD = "root"
DB_NAME = "spider01"
DB_CHARSER = "utf8"管道处理数据:在pipelines.py下(注意安装pymysql)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50class ReadbookPipeline:
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password =settings['DB_PASSWORD']
self.name =settings['DB_NAME']
self.charset =settings['DB_CHARSER']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
self.cursor.execute(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
5.日志信息与日志级别
日志级别:
1
2
3
4
5
6
7
8CRITICAL: 严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
1.从下到上级别越高
2.默认的日志等级是DEBUG,只要出现了DEBUG或者DEBUG以上等级的日志那么这些日志将会打印settings.py文件设置:
1
2
3
4
5LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_FILE='logdemo.log'
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些
LOG_LEVEL='WARNING'
6.scrapy的post请求
1.方法
1 | (1)重写start_requests方法: |
2.案例:百度翻译
创建项目
1
2
3cd C:\Users\wuhen\Desktop
scrapy startproject post_spider创建爬虫
1
2
3cd post_spider/post_spider/spiders
scrapy genspider postDemo https://fanyi.baidu.com/sug编写爬虫:post请求没有参数,则请求无意义,所以start_urls无用,parse方法无用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import scrapy
import json
class PostdemoSpider(scrapy.Spider):
name = "postDemo"
allowed_domains = ["fanyi.baidu.com"]
# post请求没有参数,则请求无意义,所以start_urls无用,parse方法无用
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw':'final'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
def parse_second(self,response):
content = response.text
obj = json.loads(content)
print(obj)
7.代理
到settings.py中,打开一个选项
1
2
3DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.Proxy': 543,
}到middlewares.py中写代码
1
2
3def process_request(self, request, spider):
request.meta['proxy'] = 'https://113.68.202.10:9999'
return None


